Avoiding (or Fixing) a Data Dumpster Fire


🟧
🟥 🟧
Garbage In, Garbage Out
You know the saying.
When you use data in your organization—for anything from reporting, analytics, automation, etc.—you run the risk of building a giant trash pile. This isn’t your fault. Sometimes it just happens as the sources of data grow and as the business requirements change.
But, we’ve seen the consequences, and they can be severe:
- Employees performing duplicate data entry
- Executives arguing over the provenance of the data
- Data products that don’t deliver on the AI hype
To get past these barriers, it is important to recognize that your data ecosystem will evolve as your organization’s needs change. Then, you can focus on laying a solid foundation for your current (or next) use case.
🟨
🟧 🟨
🟥 🟧 🟨
An Example
I’ll explain our framework below, but first a small example.
One of our clients recently wanted to record expenses for events. Ultimately they were interested in seeing how close the cost of each event was to the initial budget. The existing solution had expense records with an estimated and actual cost. This makes sense data-wise, but the challenge was that entering the actual cost for an expense required finding the initial estimate record, which was difficult. Instead, we set them up with a single data entry source where each expense was either an estimate or an actual.
We like to be pragmatic about data structures. This isn’t a perfect solution and there are definitely other ways to do it. You might argue that this design is insufficient because it doesn’t allow the client to drill down and see which items caused the event to go over or under. But, it is also important to remember that linking the expenses to their estimates would be difficult for the employees to maintain and extremely uncertain with an automated solution. Likely to lead to a data garbage pile.
Instead, our goal is to set up a foundation so that clients can build and iterate. Now the client is able to easily enter expenses and calculate overall accuracy. Additionally, they are set up to automate expense entry in the future with AI by collecting data from receipts without worrying about matching specific expense records.
🟦
🟩 🟦
🟨 🟩 🟦
🟧 🟨 🟩 🟦
🟥 🟧 🟨 🟩 🟦
The Data Product Pyramid
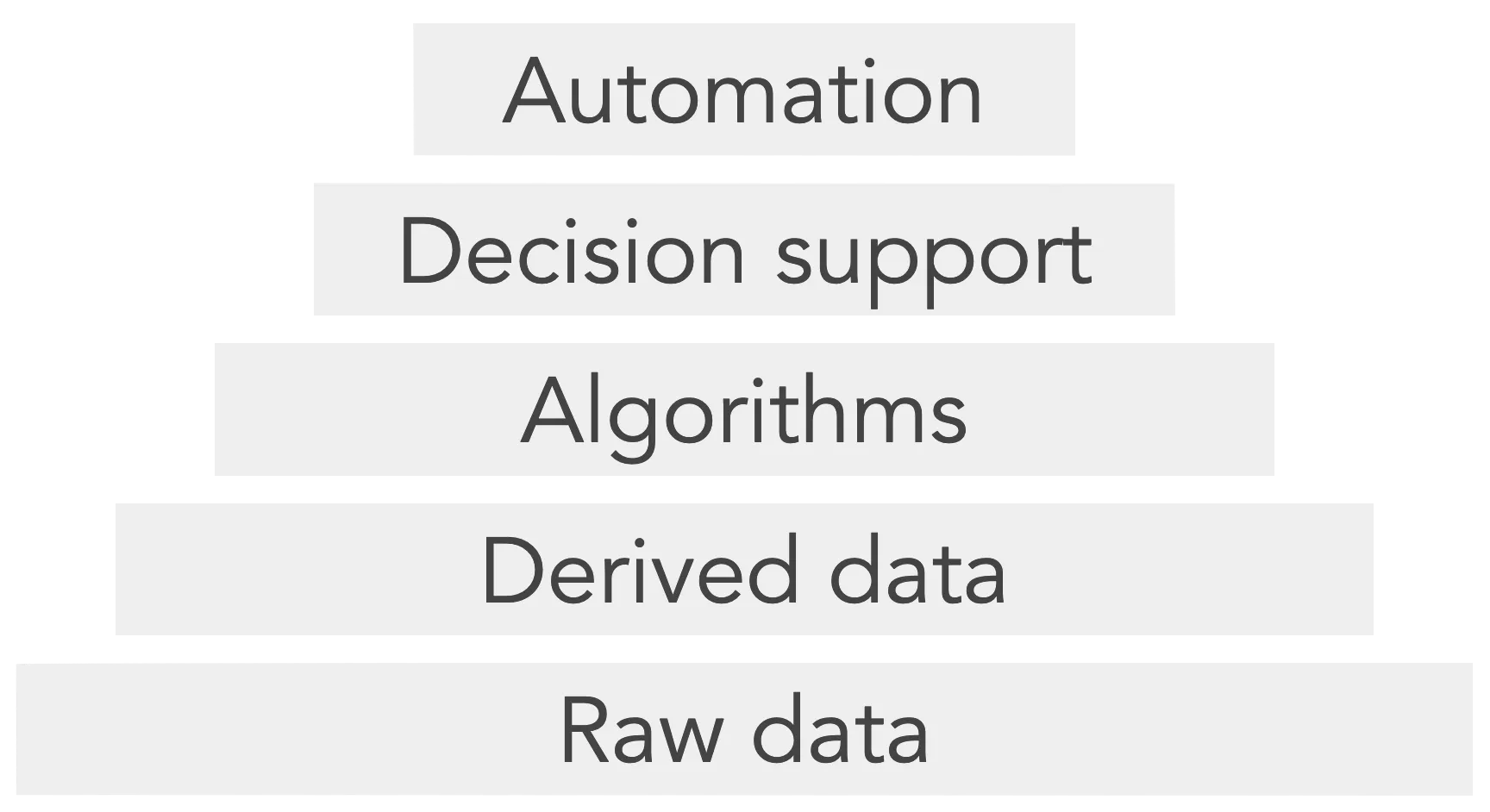
Years ago I wrote about the data product pyramid, which is a framework for understanding how data products are built. The idea is that “higher-level” outcomes—stuff like workflow automation and decision support—require a solid base layer of robust data without major gaps, inconsistent sources, and data entry errors.
When we work with clients, we emphasize the importance of continuing to check the base and expanding incrementally. Raw data are at the base because they are the least refined. Each successive level builds off of the previous in a data hierarchy of needs. This stable foundation is even more pressing as organizations try to embed AI into their processes, as these tools rely on clean and consistent inputs to produce value.
Our approach is not one-size-fits-all. Avoiding (or fixing) a data dumpster fire involves understanding where each client is headed and what they have as their current foundation. We use the data product pyramid to guide our discovery. From there, we can work together to build a great product or tool, one layer at a time.
🟪
🟦 🟪
🟩 🟦 🟪
🟨 🟩 🟦 🟪
🟧 🟨 🟩 🟦 🟪
🟥 🟧 🟨 🟩 🟦 🟪



